Data is getting generated from different sources. Walmart handles more than 1 million customer transaction every hour, Wikipedia handles billions of pages.
Skip and take me to step-by-step guide
Social networking sites Twitter, Linkedin and Facebook etc. generates new huge bytes of data in quintillion daily, the amount of data is only getting larger, deeper and more complex.
Data is considered as an asset today that’s because; its analysis adds value to business even, it is also being monetized directly or indirectly.
How information visualization add value to business?
Data is useless, if it is not adding any business value or information to empower making better decision. Some individuals learn better through visuals while others are attracted towards text.
Data in text format can be confusing but Intuitive visual representation of data helps user to make better decision quickly that in turns adds value to business.
I recently attended a seminar on “information visualization”, where speaker Aniket Mohan Sarangdhar shared his experience of the information visualization. Here in this article I am summing up the learning; I got from that seminar + my observation and experience in the same field.
Why Information Visualization?
Information visualization captures viewer’s attention and addresses complex problem through storytelling which is simplified using design. User gets information at glance to deduce insights quickly that in turns reinforce human cognition.
How to effectively convert an abstract data to visual?
In concise and simple words; understand the data first extract the data variables and match each data variable with most appropriate visual attribute. It is similar to identify which UI component is best for a specific data or task.
After mapping the data variable with visual attribute, focus on the logical placement of the different visual attributes. Now, let’s understand the terms used in above statement and the process in details with steps.
Step 1: Understand the data
As we understand the user before starting wireframing, similarly we need to understand the data for Information Visualization. The abstract data includes both quantitative (numerical) and qualitative (non-numerical) data. Let’s call it data set that will have number of data variables with different nature (type).
Classification of data type
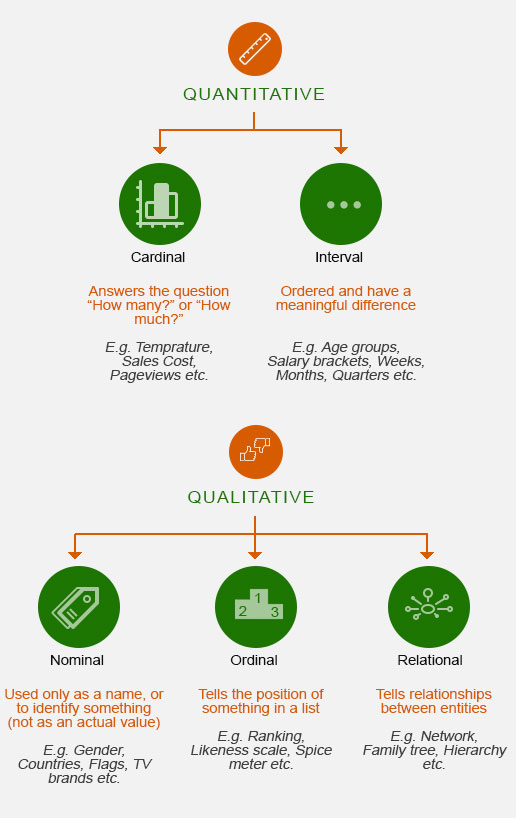
Let’s understand data type and data variable
| Data Set | Data Variable/Type |
|---|---|
| In a cricket Match Runs per over | Runs = Cardinal Overs = Nominal |
| In a weather report of Metro Cities, Sunny, Cloudy, Rainy, Thunderstorm | Cities = Nominal Types of weather = Nominal |
| In an organization No. Employees in each department | Employee = Cardinal Department = Nominal |
| Comparing spiciness of different sauces Low, Medium, High | Type of sauce = Nominal Level of spiciness = Ordinal |
| Number of users using internet in the age group 10-20, 21-30, 30-31, 31-40, 50+ | No. of users = Nominal Age group interval = Interval |
| No. of emails exchange between various department | No. of email = Cardinal Department = Nominal Exchange Linkage = Relational |
Now, after understanding the data we need to understand different visual attributes that help to create effective information visualization.
Step 2: Identify the visual attribute for data variable
Understand Visual Attributes

Now, we need to map each data variable with most appropriate visual attribute. Before that, first let’s understand visual attributes in terms of perceiving data accuracy.
Visual attributes from most accurate to least accurate in terms of representing data accuracy.
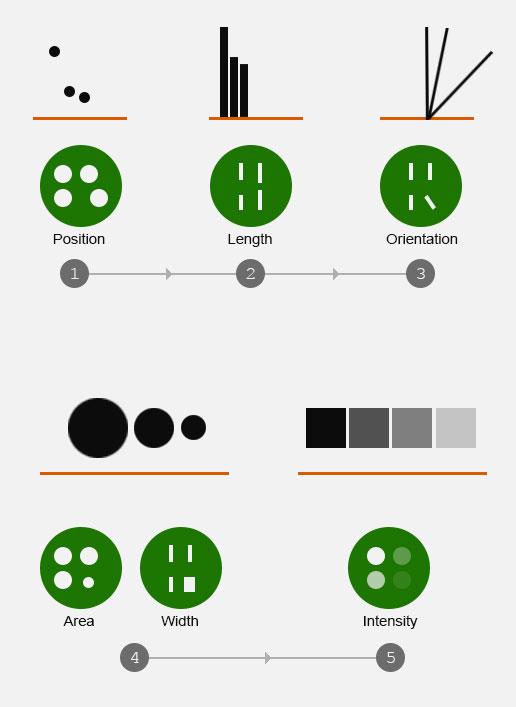
Step 3: Identify the nature of each data and map with most apropriate visual attribute
Visual attribute of data variables need to have one-to-one mapping. Visual attribute for a data can be position, length, orientation, area, shape, intensity, color etc. Each data variable needs to be mapped with one visual attribute.
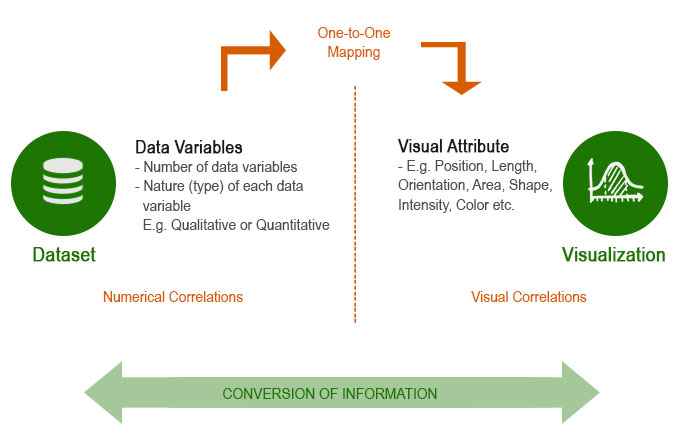
After this one-to-one mapping, focus on the logical placement of these visual attributes. So, that user can deduce insights quickly.
Let’s create basic and static information visualization using the above understanding.
| Cities | Area (Sq. Km.) | Population (millions) |
|---|---|---|
| Mumbai | 603 | 18.41 |
| Chennai | 1189 | 4.68 |
| Delhi | 1484 | 11.03 |
| Kolkata | 185 | 4.5 |
| Hydrabad | 650 | 4.5 |
Here, we have data set and we need to understand the data first. Let’s identify the data variables and data types from this data set
| Data Variables (3) | Data Type |
|---|---|
| Cities | Nominal |
| Area | Cardinal |
| Population Count | Cardinal |
We have understand the data and as a result we have data variables with data types. Now next step is; to map these data variable with most appropriate visual attribute.
| Data Variables (3) | Visual Attribute |
|---|---|
| Cities | Position |
| Area | Length |
| Population Count | Length |
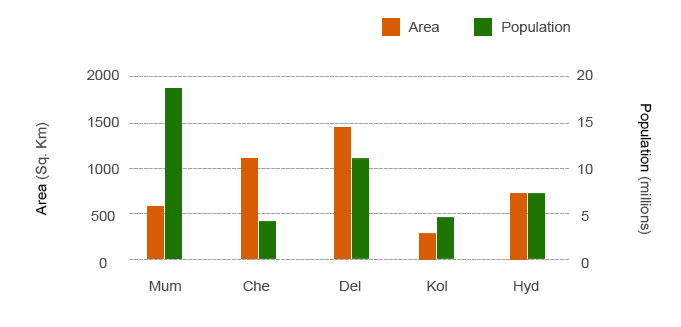
Here is the chart, where city is nominal and recognized by its position; area and population is quantitative data, where visual attribute length is used. A few points to be noted here. We have “rectangle” visual glyph and visual attribute that we have used are:
- Position
- Length
- Color
Position and Length are the two most appropriate attributes in terms of perceiving data accuracy. But the table that we created had one position and two length visual attributes. Color visual attribute was not mentioned. That was because; two data variable is mapped with same attribute i.e. length, and we need color to differentiate the variables. At the end we have 3 variables and at least 3 visual attributes, it may vary.
Data visualization can be static or interactive. Charts and maps are the examples of static visualization. But representation of huge data or data set with multiple data variable need interactive data visualization.
Next, a case study to solve the complex data visualization will be shared – Stay Tuned…